Detecting topics and themes in Dutch texts
This article describes the background and purpose of our the Dutch topic detection tool which can be tested here.
The business case for Topic Modeling
The most abundant form of information is text and human culture produces a daily flood of it. The diversity of online text goes well beyond the traditional long-read genres such as books, newspaper articles or blog posts. Tiny texts are ever abundant: businesses project notes, internal discussions, memos, ancient correspondence, online reviews, Instagram and Twitter messages.
Organizations easily assume texts they store or process have been assigned sufficient metadata for all future purposes. Customer e-mail conversations may have been assigned a fixed set of categories (such as: ‘complaint about lost delivery’, ‘workplace incident rapport’, …) in the past, but such categories are never stale. New categories will be required, with existing correspondence not automatically connected to those categories. Similarly, a news site may have started using a tag scheme at some point-in-time, but continuously adds relevant, trending tags to their articles. How is it able to properly cluster articles (for search and recommendation purposes) without a consistent taxonomy? How can it relate an older article studying the threat of pandemics to a recent article about the Corona virus? Text mining and topic modeling offer solutions to these types of issues. They allow organizations to gain a far greater insight into the entirety of their text corpus and open up new data potential.
Once a big Tourist & Travel organization has applied topic modeling to its historical customer interaction data (with complaints, experiences and suggestions from its customers), it can automatically discover common problems and frustrations. It can easily connect specific types of complaints to certain travel destinations. It can extract common themes from across the thousands of suggestions they have accumulated over the years, to make better founded decisions on what aspects of their service to improve. Finally, by applying trend detection, it can flag problems early and take timely action to resolve complaints. Or, if used in conjunction with emotion analysis, the travel agency may be able to discover which types of accommodations and services are gaining favor with tourists and make business decisions using this knowledge.
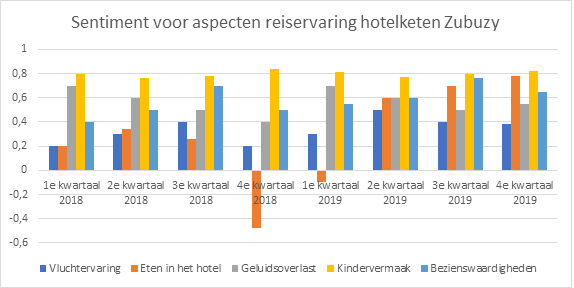
Example: Topic modeling can enable aspect-based sentiment analysis, as in the example above, for a fictional Dutch Hotel franchise called Zubuzy. The customer experience categories aren’t given in advance, but are learned using topic modeling. The most prominent topics are visualized above. Customer experience is connected with positive or negative emotions. Trend detection flags a sudden drop in the quality of food in the 4th quarter of 2018, related to a switch in catering service. Mitigating measures are taken and customer satisfaction quickly rises again.
The big advantage of text mining is that it lets the data speak for itself. It is always possible to have a domain expert design a system of classes (a taxonomy) where this expert defines the categories in advance and a machine-learning classifier is trained to assign those classes to new, unseen documents. At InterTextueel we have built many such text classification systems and they tend to perform well. But topic modeling allows us to detect themes and topics that are latently present in the data itself. Topics that we didn’t yet know about, but should. We will show how a generic topic modeling system works, by building one based on the broadest possible range of text data. We will call it the Universal Topic Model.
Text summarization technologies
Let’s start by looking at the different Natural Language Processing technologies available to produce keywords and summaries for text. There are three fundamental approaches. Summarizing keywords aim to produces relevant tag-like keywords for a given text. Those keywords need not be literally present in the original source text. They can be considered representative of broader topics. For instance, a journalistic article about the rapid decline of the Dutch stock market may be labeled “Economic crisis” even though that literal phrase is missing in the article itself. This is very much akin to how humans would label texts.
Extractive keywords are prominent, or meaningful phrases extracted from the document itself. They are typically much more specific to the article and the text. A soccer discussion about a recent match in the Dutch Premier League can have the specific names of the soccer teams or goal getters extracted from the text. This information helps clustering highly specific topics. The third form of summarization is called “abstractive summarization”. Here we produce a much shorter textual description of the full text, in human readable language. We focus on re-assembling the most meaningful sentences in the in text into a coherent summary.
Ensemble method
Our Universal Topic Model will be an ensemble of different technologies: summarizing topic modeling and extractive topic modeling, including named entity recognition. While abstractive summarization is useful for different purposes, it does not yield rich metadata (keywords) to easily compare documents inside a corpus. Keywords help turn unstructured data into enriched data. They allow us to discover and visualize historical trends and distributions and help organizations and customers better navigate data.
The training set
Building a summarizing keyword generator requires training data. The training data does not have to be labeled in advance. Our training data currently holds nearly 20 million short paragraphs, ranging from medium/short texts to longer articles. The texts are publicly sourced, by web crawl and by accessing publicly available archives. The full Dutch Wikipedia represents a subset, but we are using many different additional sources because we do not want to produce an “academic” keyword generator. Instead, we’d like to capture the widest range of Human interests and activities as possible. Topic models can contain the names of persons, locations, organizations et cetera. We want to prevent the topic model from capturing data about individual persons, even though such individuals would be statistically “drowned” in the model and would be extremely unlikely to affect keyword generation. The exceptions are very well-known persons, such as presidents of countries, sport heroes, movie stars, etc. Their mentions are relevant to our model, without which it fails to recognize important cultural and political references.
Our method to achieve aggressive anonymization of the input texts is filtering the text through a pre-defined n-gram dictionary before training the topic model itself. Any data about individual persons will thus be discarded at the onset, because such individuals will not be present in the whitelisted list of “famous persons”. An additional advantage of using the n-gram whitelist, is noise reduction. Superfluous, non-Dutch tokens will not be able to enter the topic model.
The algorithms
In this section we are forced to be less chatty about the specifics. Natural Language Processing researchers will be familiar with the existing set of technologies available for Topic Modeling: Latent Dirichlet Allocation, Non-negative Matrix Factorization, clustering by Doc2Vec vectors et cetera. To build your own topic models, you can come a long way with Python scripting and tutorials. But the products we build and launch in our API are the result of many, many months of fine-tuning specific models, applying rather sophisticated forms of tokenization and a lot of human hand-work. We have annotated the final summarizing topic model by hand and developed technology to semi-automatically update annotations given new data in the future. Whatever we can contribute back to open source development of important libraries, we do, but we cannot discuss in detail the end-technology behind our topic modeling system.
The keywords
The latest version (June 22 – 2020) of the Universal Topic model produces 895 broad, summarizing keywords. The list can be downloaded here. A first glance clearly reveals the topic model is based on Dutch text sources and represent important Dutch cultural interests. It actually does so with remarkable clarity. Take politics for example. We have multiple keywords describing Dutch politics (parliament, cabinet, political parties et cetera.) and a distinct keyword describing the politics of our surrounding countries. The United States is a notable exception to the proximity effect, as its politics are frequently discussed in the Netherlands. The focus on particularities of the Dutch speaking community is precisely the most powerful aspect of the model. We did not wish to wield the wand of philosophy and develop an ontological edifice of perfect keywords in advance. Instead, we have obtained an accurate representation of what people are actually discussing most frequently using our method. It becomes immediately clear which sports are entertained the most in the Netherlands. Soccer has keywords for multiple aspects of the sport, including match results, specific competitions et cetera. Cycling and swimming have fewer keywords, but are also clearly present. The final goal is to have an umbrella to match as much of human interests as possible. It may be necessary to perform targeted web searches to enhance the retrieval of particular keywords for underrepresented domains.
Conclusion
Our system produces high-quality keywords for any given Dutch text and can be used to start text mining immediately. In addition, it extracts prominent phrases to attain a more detailed representation. However, because it is not domain specific, it may not be fine-grained enough for your organization’s ultimate purposes. InterTextueel offers a reasonably priced service to train our technology on your own dataset and provide tailored topic modeling. The ease of access (i.e. using simple API calls) and the classification speed will remain the same. Please contact us at any time to discuss the possibilities.
The first version of the Universal Topic Model went into production 15th of April 2020. Feel free to test it on our demo page. For commercial use, API accounts are available at monthly costs. We are testing the existing model for as much domains as possible and welcome end-user feedback. We will be continuously expanding and improving the model.